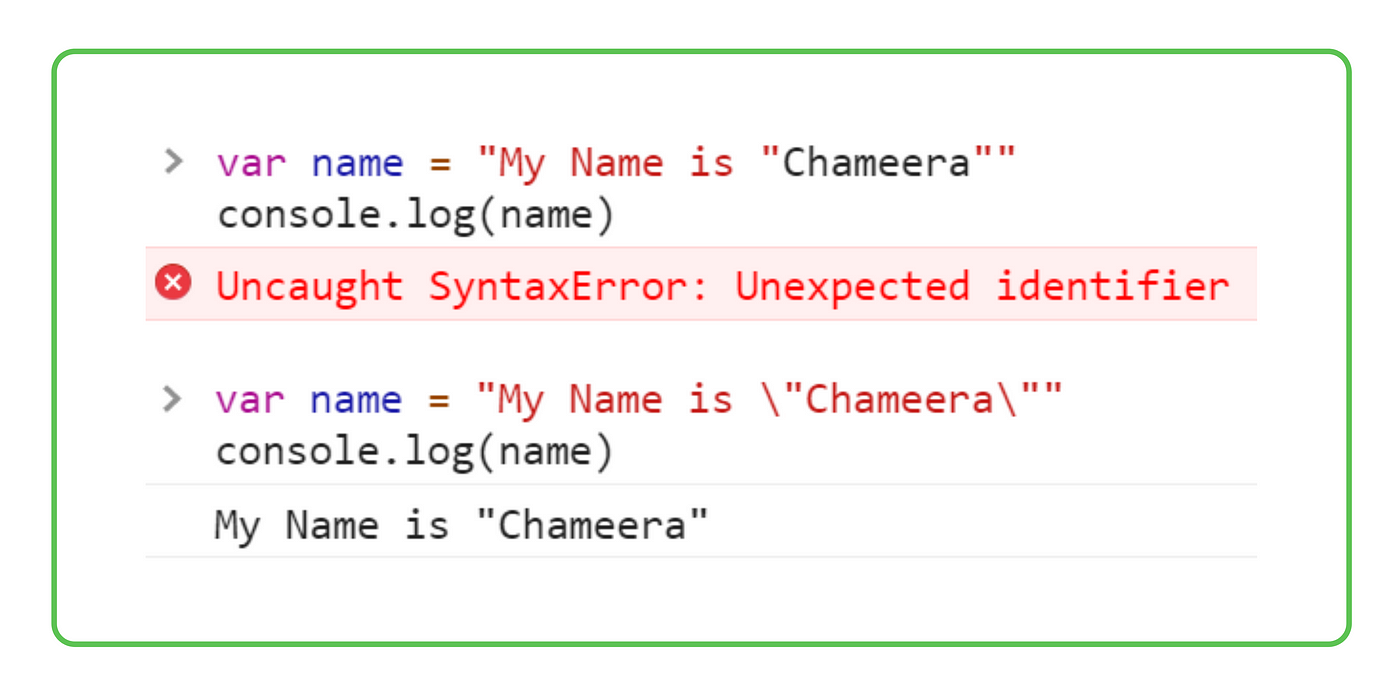
Spark Sql Escape Double Quote

Imagine you're throwing a costume party. Your database is like the guest list, meticulously organized. Each guest (or data point) has a name and a costume description. But what happens when a guest decides to wear a costume that includes quotation marks – like, say, someone dressed as a character who's famous for saying, "Frankly, my dear, I don't give a damn!" Now you've got quotation marks inside the quotation marks that define the costume description. It's a quotation-mark-ception! And that's where the fun – or the potential chaos – begins when you're using Spark SQL.
See, Spark SQL, that clever tool for querying data, uses double quotes to identify text, kind of like putting each costume description inside a pair of parenthesis. So, if a description already contains a double quote, Spark gets confused. It’s like trying to explain a joke that uses the punchline in the explanation itself. "Knock, knock." "Who's there?" "Interrupting cow." "Interrupting cow wh–" "MOO!" ... but the "moo" is ALSO part of the original setup. Brain...hurts!
That's where the "escape" comes in. Think of "escaping" a double quote as putting a little bodyguard in front of it – like adding a small code symbol—usually a backslash (\)—that politely whispers to Spark, "Hey, that double quote there? It's not the end of the string. It's part of the costume description. Chill out." The backslash effectively tells Spark to interpret the double quote literally, as just another character within the text, not as the signal to stop reading.
Must Read
Let's say one of your data points is a character named “Eleanor” whose description is "She said, 'Wow, that's \"amazing\"!'". You wouldn't want Spark to read that as “She said, 'Wow, that's " and then just stop, dropping the last bits of the description like a clumsy waiter spilling soup. No, you need to escape those inner quotes! That's where you'd turn it into something like: "She said, 'Wow, that's \\"amazing\\"!'"
The Backslash: Tiny Hero of Data
It might sound tedious, this whole "escaping" thing. But picture the alternative! Without it, your data would be a mess. Instead of neatly organized information, you'd have fragments of sentences, truncated details, and a whole lot of frustration. The tiny backslash, that seemingly insignificant character, becomes a hero, maintaining order in the digital universe. It's like that one person at the party who knows how to untangle the Christmas lights; essential but rarely thanked directly.
Consider a dataset of movie quotes. Imagine trying to analyze which movies used the word “love” the most often. If you have quotes like, "I love you, she said, \"more than words can express,\"" without escaping the inner quotes, your count would be way off! Spark might just see "I love you, she said," and ignore the rest. All that carefully crafted dialogue, lost to the ether because of a rogue double quote.

This isn't just about accuracy; it's about the story. Data isn't just numbers and letters; it represents people, events, and ideas. The escape sequence is crucial in maintaining data integrity, ensuring that Spark SQL can correctly interpret and analyze information. It allows analysts and researchers to extract meaningful stories from their datasets accurately and efficiently, and prevent a data disaster on a grand scale.
So, next time you see a backslash patiently guarding a double quote within your Spark SQL code, give it a mental pat on the back. It's a small thing, sure. But it's saving your data from a quotation-mark-induced catastrophe. It's the unsung hero, the quiet guardian, the backslash that whispers, "All is well. The story remains intact." Just remember “Escaping the character” is key.